图像识别没你想的那么难!看完这篇你也能成专家
本地生活场景中包含大量极富挑战的计算机视觉任务,如菜单识别,招牌识别,菜品识别,商品识别,行人检测与室内视觉导航等。

这些计算机视觉任务对应的核心技术可以归纳为三类:物体识别,文本识别与三维重建。
2018 年 11 月 30 日-12 月 1 日,由 51CTO 主办的 WOT 全球人工智能技术峰会在北京粤财 JW 万豪酒店隆重举行。
本次峰会以人工智能为主题,阿里巴巴本地生活研究院人工智能部门的负责人李佩和大家分享他们在图像识别的过程中所遇到各种问题,以及寻求的各种解法。
什么是本地生活场景

我们所理解的本地生活场景是:从传统的 O2O 发展成为 OMO(Online-Merge-Offline)。
对于那些打车应用和饿了么外卖之类的 O2O 而言,它们的线上与线下的边界正在变得越来越模糊。
传统的线上的订单已不再是只能流转到线下,它们之间正在发生着互动和融合。

在 2018 年,我们看到滴滴通过大量投入,组建并管理着自己的车队。他们在车里装了很多监控设备,试图改造线下的车与人。
同样,对于饿了么而言,我们不但对线下物流的配送进行了改造,而且尝试着使用机器人,来进行无人配送、以及引入了智能外卖箱等创新。
可见在本地生活场景中,我们的核心任务就是将智能物联(即 AI+IoT)应用到 OMO 场景中。
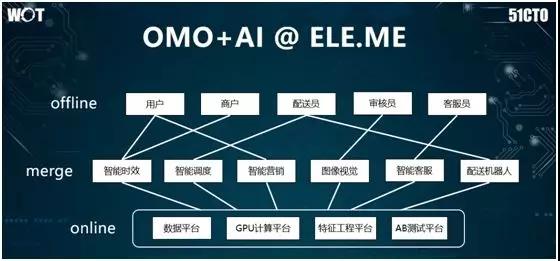
上图是阿里巴巴本地生活饿了么业务的人工智能应用的逻辑架构。和其他所有人工智能应用计算平台类似,我们在底层用到了一些通用的组件,包括:数据平台、GPU 平台、特征工程平台、以及 AB 测试平台。
在此之上,我们有:智能配送、分单调度和智能营销等模块。同时,算法人员也进行了各种数据挖掘、机器学习和认准优化。

目前对于阿里巴巴的本地生活而言,我们的图像视觉团队承担着整个本地生活集团内部,与图像及视觉相关的所有识别和检测任务。而所有的图像处理都是基于深度学习来实现的。
我将从如下三个方面介绍我们的实践:
物体的识别。
文本的识别。此处特指对于菜单、店铺招牌、商品包装图片文字的识别,而非传统意义上对于报纸、杂志内容的识别。
三维重建。
物体识别

在我们的生活场景中,有着大量对于物体识别的需求,例如:
饿了么平台需要检测骑手的着装是否规范。由于骑手众多,光靠人工管控,显然是不可能的。
因此在骑手的 App 中,我们增加了着装检测的功能。骑手每天只需发送一张包含其帽子、衣服、餐箱的自拍照到平台上,我们的图像算法便可在后台自动进行检测与识别。
通过人脸的检测,我们能够认清是否骑手本人,进而检查他的餐箱和头盔。
场景目标识别。通过检测行人、办公区的桌椅、以及电梯的按钮,保障机器人在无人配送的生活场景中认识各种物体。
合规检测。由于饿了么平台上有着大量的商品、餐品和招牌图片,营业执照,卫生许可证,以及健康证等。
因此我们需要配合政府部门通过水印和二维码,来检查各家餐馆的营业执照和卫生许可证是否被篡改过。
另外,我们也要求餐馆的菜品图片中不能出现餐馆的招牌字样。这些都会涉及到大量的计算机视觉处理。
场景文本识别。在物体识别的基础上,通过目标检测的应用,对物体上的文字进行识别,如:菜单里的菜品和菜价。

对于图片目标的检测评价,目前业界有两个指标:
平均检测精度。即物体框分类的准确性。先计算每个类别的准确性,再求出所有类别的准确性。
IOU(交并比)。即预测物体框与实际标准物体框之间覆盖度的比例,也就是交集和并集的比例。
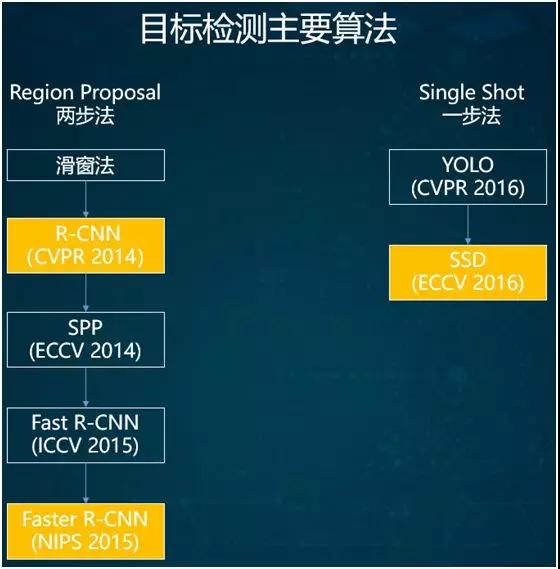
上图列出了目标检测的常用基础算法,它们分为两类:
两步法
一步法
两步法历史稍久一些,它源于传统的滑窗法。2014 年,出现了采用深度学习进行目标检测的 R-CNN。
之后又有了金字塔池化的 SPP 方法,以及在此之上研发出来的 Fast R-CNN 和 Faster R-CNN 两个版本。
当然,Faster R-CNN 算法在被运用到机器人身上进行实时检测时,为了达到毫秒级检测结果的反馈,它往往会给系统的性能带来巨大的压力。
因此,有人提出了一步法,其中最常用的是在 2016 年被提出的 SSD 算法。
虽然 2017 年、2018 年也出现了一些新的算法,但是尚未得到广泛的认可,还需进一步的“沉淀”。
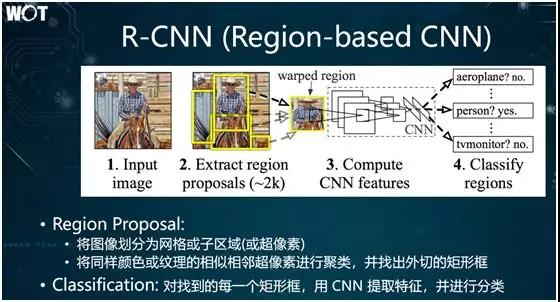
下面,我们来讨论那些针对不同场景目标的解决算法。在此,我不会涉及任何的公式,也不会涉及任何的推导,仅用简单浅显的语言来描述各个目标检测算法背后的核心思想。
R-CNN 的简单思路是:
Region Proposal。首先,将目标图像划分成许多个网格单元,这些网格被称为超像素;然后,将同样颜色或纹理的相似相邻超像素进行聚类,并找出外切的矩形框。该矩形框便称为 Region Proposal。
Classification。首先用 CNN 提取特征;再得到卷积的线性图,然后再用 SoftMax 或者其他的分类方法进行普通分类。

各种上述 R-CNN 流程最大的问题在于:产生的候选框数量过多。由于矩形框的形状,包括长度、宽度、中心坐标等各不相同,因此如果一张图中包含的物体过多,则找出来的矩形框可达成千上万个。
鉴于每个候选框都需要单独做一次 CNN 分类,其整体算法的效率并不高。当然,作为后期改进算法的基础,R-CNN 提供了一种全新的解决思路。
SPP(空间金字塔池化)的特点是:
所有的候选框共享一次卷积网络的前向计算。即:先将整张图进行一次性 CNN 计算,并提取特征后,然后在特征响应图上进行后续的操作。由于仅作卷积计算,其性能提升了不少。
通过金字塔结构获得在不同尺度空间下的 ROI 区域。即:通过将图片分成许多不同的分辨率,在不同的尺度上去检测物体。
例如:某张图片上既有大象,又有狗,由于大象与狗的体积差异较大,因此传统 R-CNN 检测,只能专注大象所占的图像面积。
而 SPP 会将图像缩小,以定位较小的图片。它可以先检测出大象,再通过图像放大,检测出狗。可见它能够获取图像在不同尺度下的特征。
FastR-CNN 在简化 SPP 的同时,通过增加各种加速的策略,来提升性能。不过,它在算法策略上并无太大的变动。
FasterR-CNN 创造性地提出了使用神经网络 RPN(Region Proposal Networks),来代替传统的 R-CNN 和 SPP,并得到了广泛的应用。
它通过神经网络来获取物体框,然后再使用后续的 CNN 来对物体框进行检测,进而实现了端到端的训练。
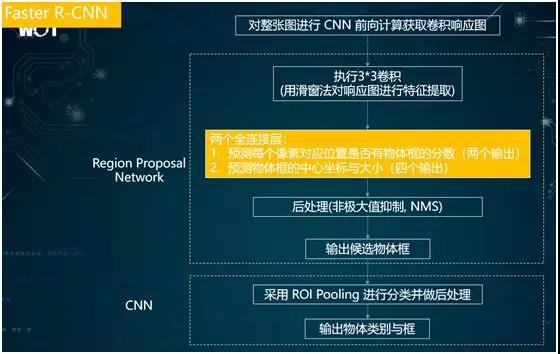
上图是我整理的 Faster R-CNN 执行逻辑框架图,其流程为:
使用 CNN 计算出图像的卷积响应图。
执行 3×3 的卷积。
使用两个全连接层,预测每个像素所对应的位置是否有物体框的出现,进而产生两个输出(“是”的概率和“否”的概率)。
如果有物体框的输出,则预测物体框中心坐标与大小。此处有四个输出(中心坐标的 X 和 Y,以及长和宽)。因此,对于每个物体框来说,共有六个输出。
使用通用的 NMS 进行后处理,旨在对一些重叠度高的物体框进行筛选。例如:图中有一群小狗,那么检测出来的物体框就可能会重叠在一起。
通过采用 NMS,我们就能对这些重合度高的框进行合并或忽略等整理操作,并最终输出物体的候选框。
采用 CNN 进行分类。
可见,上述提到的各种两步方法虽然精度高,但是速度较慢。而在许多真实场景中,我们需要对目标进行实时检测。
例如:在无人驾驶时,我们需要实时地检测周围的车辆、行人和路标等。因此,一步方法正好派上用场。YOLO 和 SSD 都属于此类。

YOLO 方法的核心思想是:对于整张图片只需要扫描一次,其流程为:
使用 CNN 获取卷积响应图。
将该响应图划分成 S*S 个格子。
使用两个全连接层来预测物体框的中心坐标与大小,以及格子在物体类别上的概率。
将图片中所有关于物体检测的信息存入一个 Tensor(张量)。
使用后处理,输出物体的类别与框。
由于此方法较为古老,因此在实际应用中,一般不被作为首选。
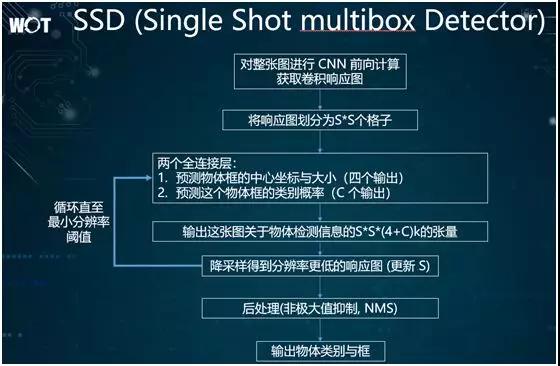
作为我们的首选,SSD 采用了一种类似于金字塔结构的处理方法。它通过循环来对给定图片不断进行降采样,进而得到分辨率更低的另外一张图片。
同时,在降采样之后的低分辨率图片上,该方法还会反复进行物体检测,以发觉物体的信息。
因此,SSD 的核心思想是:将同一张图片分成了多个级别,从每个级别到其下一个级别采用降采样的方式,从而检测出每个级别图片里的物体框,并予以呈现。
可见,对于 YOLO 而言,SSD 能够发现不同分辨率的目标、发掘更多倍数的候选物体框,在后续进行重排序的过程中,我们会得到更多条线的预定。
当然 SSD 也是一种非常复杂的算法,里面含有大量有待调整的细节参数,因此大家可能会觉得不太好控制。
另外,SSD 毕竟还是一种矩形框的检测算法,如果目标物体本身形状并不规则,或呈现为长条形的话,我们就需要使用最新的语音分割来实现。
文本识别

除了通过传统的 OCR 方法,来对身份证、健康证、营业执照进行识别之外,我们还需要对如下场景进行 OCR 识别:
通过识别店铺的招牌,以保证该店铺上传的照片与其自身描述相符。
通过对小票和标签之类票据的识别,把靠人流转的传统物流过程,变成更加自动化的过程。
对各式各样的菜单进行识别。

传统的 OCR 流程一般分为三步:
简单的图像处理。例如:根据拍摄的角度,进行几何校正。
提取数字图像的特征,进行逐个字符的切割。
对于单个字符采用 AdaBoost 或 SVM 之类的统计式机器学习,进而实现光学文字识别。
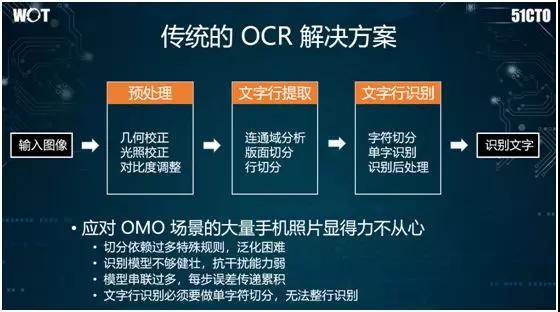
但是鉴于如下原因,该流程并不适合被应用到店铺的菜单识别上:
由于过多地依赖于摄像角度和几何校正之类的规则,因此在处理手机拍摄时,会涉及到大量半人工的校正操作。
由于目标文字大多是户外的广告牌,会受到光照与阴影的影响,同时手机的抖动也可能引发模糊,所以传统识别模型不够健壮,且抗干扰能力弱。
由于上述三步走的模型串联过多,因此每一步所造成的误差都可能传递和累积到下一步。
传统方法并非端到端模式,且文字行识别必须进行单字符切分,因此无法实现对整行进行识别。

因此,我们分两步采取了基于深度学习的识别方案:文字行检测+文字行识别。
即先定位图片中的文字区域,再采用端到端的算法,实现文字行的识别。
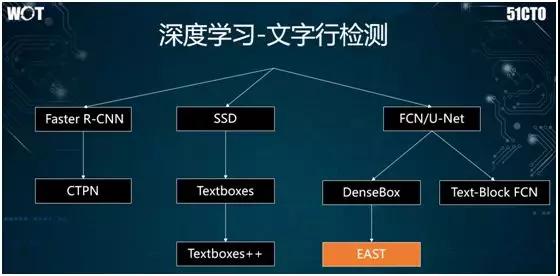
如上图所示,文字行的检测源于物体识别的算法,其中包括:
由 Faster R-CNN 引发产生了 CTPN 方法,专门进行文字行的检测。
由 SSD 引出的 Textboxes 和 Textboxes++。
由全卷积网络或称为 U-Net 引出的 EAST 等。
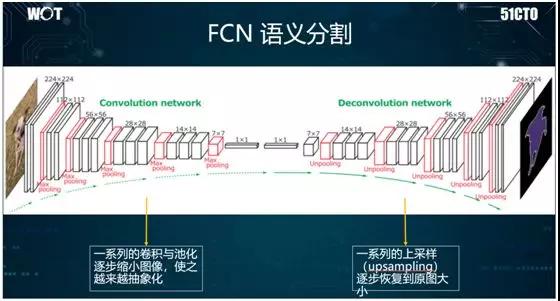
说到全卷积网络(FCN),它经常被用来进行语义分割,而且其 OCR 的效果也是最好的。
从原理上说,它采用卷积网络,通过提取特征,不断地进行卷积与池化操作,使得图像越来越小。
接着再进行反卷积与反池化操作,使图像不断变大,进而找到图像物体的边缘。因此,整个结构呈U字型,故与 U-Net 关联性较强。
如上图所示:我们通过将一张清晰的图片不断缩小,以得到只有几个像素的蓝、白色点,然后再将其逐渐放大,以出现多个蓝、白色区域。
接着,我们基于该区域,使用 SoftMax 进行分类。最终我们就能找到该图像物体的边缘。

经过实践,我们觉得效果最好的方法是基于全卷积网络的 EAST。如上图所示,其特点是能够检测任意形状的四边形,而不局限于矩形。
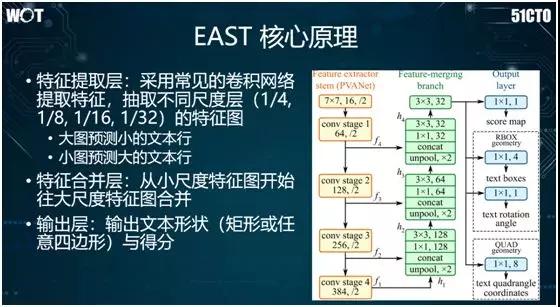
EAST 的核心原理为:我们对上图左侧的黄色区域不断地进行卷积操作,让图像缩小。在中间绿色区域,我们将不同尺度的特征合并起来。
而在右侧蓝色区域中,我们基于取出的特征,进行两种检测:
RBOX(旋转的矩形框),假设某个文字块仍为矩形,通过旋转以显示出上面的文字。
QUAD(任意四边形),给定四个点,连成一个四边形,对其中的文字进行检测。
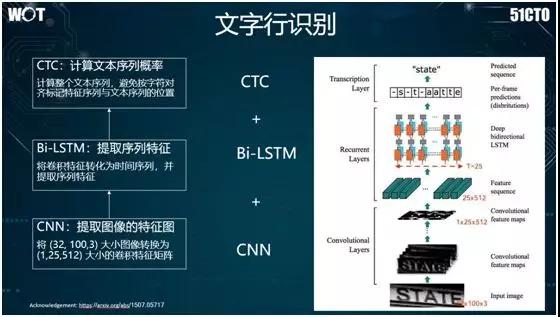
对于文字行的识别,目前业界常用的方法是 CTC+Bi-LSTM+CNN。如上图所示,我们应该从下往上看:首先我们用 CNN 提取给定图像的卷积特征响应图。
接着将文字行的卷积特征转化为序列特征,并使用双向 LSTM 将序列特征提取出来;最后采用 CTC 方法,去计算该图像的序列特征与文本序列特征之间所对应的概率。

值得一提的是,CTC 方法的基本原理为:首先通过加入空白字符,采用 SoftMax 进行步长特征与对应字符之间的分类。
籍此,对于每个图像序列,它都能得到字符序列出现的概率。然后通过后处理,将空白字符和重复符号删除掉,并最终输出效果。
三维重建
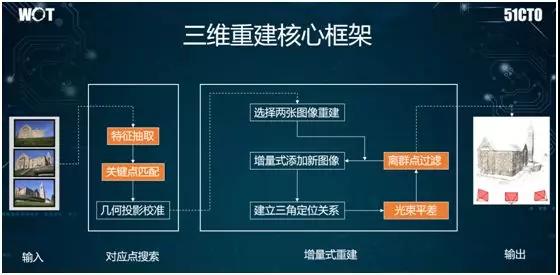
在无人驾驶的场景中,我们有时候可能需要通过移动摄像头,将采集到的数据构建出建筑物的三维结构。
如上图所示,其核心框架为:首先对各种给定的图片进行不只是 CNN 的特征提取,我们还可以用 SIFT 方法(见下文)提取其中的一些角点特征。
然后,我们对这些角点进行三角定位,通过匹配找到摄像头所在的空间位置。
最后我们使用光束平差,来不断地构建空间位置与摄像头本身的关系,进而实现三维构建。
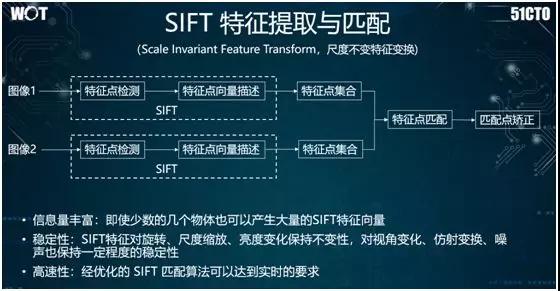
上面提到了 SIFT 特征提取,它的特点是本身的速度比较慢。因此为了满足摄像头在移动过程中进行近实时地三维构建,我们需要对该算法进行大量的调优工作。
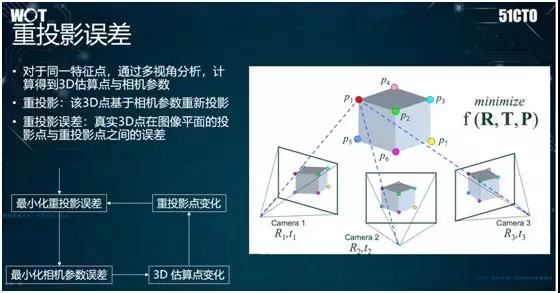
同时,在三维重建中,我们需要注意重投影误差的概念。其产生的原因是:通常,现实中的三维点落到摄像机上之后,会被转化成平面上的点。
如果我们想基于平面的图像,构建出一个三维模型的话,就需要将平面上的点重新投放到三维空间中。
然而,如果我们对摄像机本身参数的估算不太准确,因此会造成重新投放的点与它在三维世界的真正位置之间出现误差。
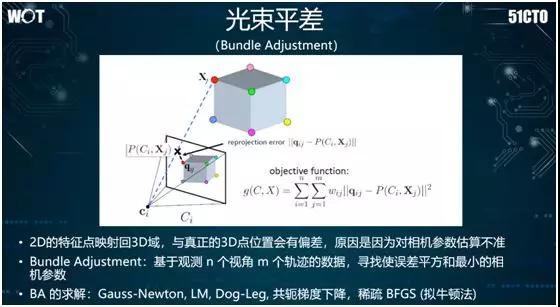
如前所述,我们还可以使用光束平差来求解矩形的线性方程组。通常它会用到稀疏 BFGS(拟牛顿法)去进行求解,进而将各个三维的点在空间上予以还原。
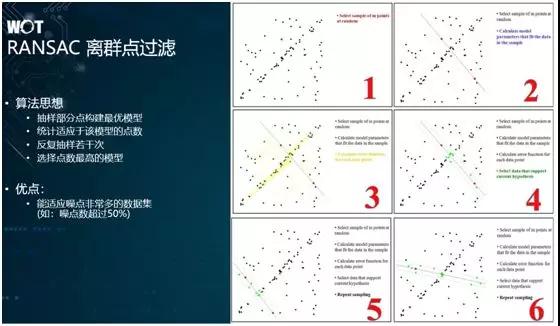
最后一步是关于离群点的过滤。由于我们在做三维重建的过程中,会碰到大量的噪点,那么为了过滤它们,我们会使用 RANSAC 方法来进行离群点的过滤。
从原理上说,它会不断随机地抽取部分点,并构建自由模型,进而评比出最佳的模型。

如上图所示,由于上方两张图里有着大量的边缘位置特征,我们可以通过 RANSAC 离群点过滤,将它们的特征点对应起来,并最终合成一张图。而且通过算法,我们还能自动地发觉第二张图在角度上存在着倾斜。
总的说来,我们在物体识别、文本识别、以及三维重建领域,都尝试了大量的算法。希望通过上述分析,大家能够对各种算法的效果有所认识与了解。
作者:李佩
简介:阿里巴巴本地生活研究院人工智能部门负责人